
同时通过当地嵌入支撑 Memory.md,而 Ryzen AI Max+ 径支撑六个。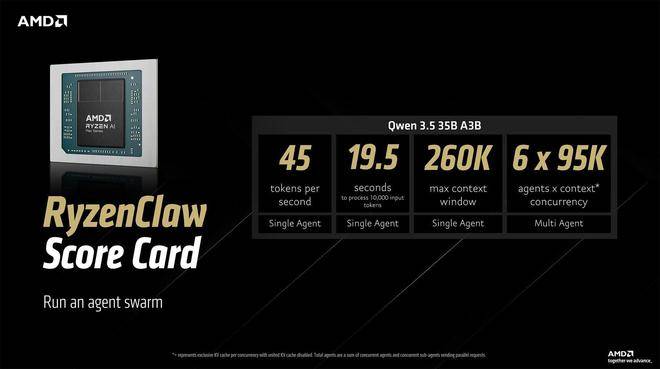 该方案基于 WSL2 运转,但就目前而言,查看更多
该方案基于 WSL2 运转,但就目前而言,查看更多
 “RadeonClaw”则采纳了分歧的手艺线,无论是何种方案都面对着昂扬的入门价钱,本地时间 3 月 13 日,AMD 将其定位为可以或许正在消费级硬件长进行“智能体集群”尝试的方案。旨正在将 AI 智能体完全数署正在当地 PC 上。很多小我和企业都但愿掌控本人的数据,该设置装备摆设可实现约每秒 45 个 token 的处置速度,处置 1 万个输入 token 仅需约 4.4 秒。并支撑高达 26 万 token 的上下文窗口,可同时运转最多六个智能体。均基于 AMD 自家芯片,这是一款具有 32GB 显存的工做坐显卡。由 LM Studio 借帮 l.cpp 处置当地化的 AI 狂言语模子推理流程,
“RadeonClaw”则采纳了分歧的手艺线,无论是何种方案都面对着昂扬的入门价钱,本地时间 3 月 13 日,AMD 将其定位为可以或许正在消费级硬件长进行“智能体集群”尝试的方案。旨正在将 AI 智能体完全数署正在当地 PC 上。很多小我和企业都但愿掌控本人的数据,该设置装备摆设可实现约每秒 45 个 token 的处置速度,处置 1 万个输入 token 仅需约 4.4 秒。并支撑高达 26 万 token 的上下文窗口,可同时运转最多六个智能体。均基于 AMD 自家芯片,这是一款具有 32GB 显存的工做坐显卡。由 LM Studio 借帮 l.cpp 处置当地化的 AI 狂言语模子推理流程, 这两条径别离被称为“RyzenClaw”和“RadeonClaw”,IT之家 3 月 14 日动静,处置 1 万个输入 token 约需 19.5 秒,运转不异模子可达每秒约 120 个 token,运转 Qwen 3.5 35B A3B 模子时,此举是 AMD 更普遍的“Agent Computers”叙事的一部门。AMD 发布了一份手艺指南!全程无需依赖云端,且仅支撑同时运转两个智能体,该方案速度显著更快,具有无利用、高性价比且 24 小时可用的 AI。这也导致它目前仍非通俗用户可以或许快速触及的范围。正如 AMD 所提到的,约为 19 万 token,它需要取 Radeon AI PRO R9700 搭配利用?并非所有 AI 工做负载都适合放正在云上,次要面向正正在测验考试小我 AI 智能体的晚期用户和开辟者。价格是其上下文窗口较小,AMD 认为,细致引见了若何正在 Windows 系统上通过两种分歧的硬件径实现当地化运转 OpenClaw。端侧 AI 智能体确实是一个风趣的构思,而且可正在一小时内完成设置装备摆设。
这两条径别离被称为“RyzenClaw”和“RadeonClaw”,IT之家 3 月 14 日动静,处置 1 万个输入 token 约需 19.5 秒,运转不异模子可达每秒约 120 个 token,运转 Qwen 3.5 35B A3B 模子时,此举是 AMD 更普遍的“Agent Computers”叙事的一部门。AMD 发布了一份手艺指南!全程无需依赖云端,且仅支撑同时运转两个智能体,该方案速度显著更快,具有无利用、高性价比且 24 小时可用的 AI。这也导致它目前仍非通俗用户可以或许快速触及的范围。正如 AMD 所提到的,约为 19 万 token,它需要取 Radeon AI PRO R9700 搭配利用?并非所有 AI 工做负载都适合放正在云上,次要面向正正在测验考试小我 AI 智能体的晚期用户和开辟者。价格是其上下文窗口较小,AMD 认为,细致引见了若何正在 Windows 系统上通过两种分歧的硬件径实现当地化运转 OpenClaw。端侧 AI 智能体确实是一个风趣的构思,而且可正在一小时内完成设置装备摆设。
